Many underwater tasks, such as cable-and-wreckage inspection, search-and-rescue, benefit from robust human-robot interaction (HRI) capabilities. With the recent advancements in vision-based underwater HRI methods, autonomous underwater vehicles (AUVs) can communicate with their human partners even during a mission. However, these interactions usually require active participation especially from humans. Almost all of the time, the divers are required to swim towards the AUV, orient themselves correctly with respect to the AUV, begin the interaction, and continue to look at the robot during the whole interaction. As a result, the divers experience additional physical and cognitive burdens. To address these issues, the work in [1] proposes a method for the AUVs to approach a human diver by leveraging their body pose and biological priors to facilitate HRI. However, the proposed solution always assumes that a diver is ready to interact. There are times when a diver may be engaged in a different task or interaction with a fellow dive buddy but is still willing to interact with a robot only if the robot positions itself conveniently. In such scenarios, it is imperative for the AUVs to understand the intent of the diver, more specifically their attentiveness (as shown in Fig. 1). By “attentiveness”, we refer to whether or not a diver is looking at a robot with an intention to interact and/or collaborate.
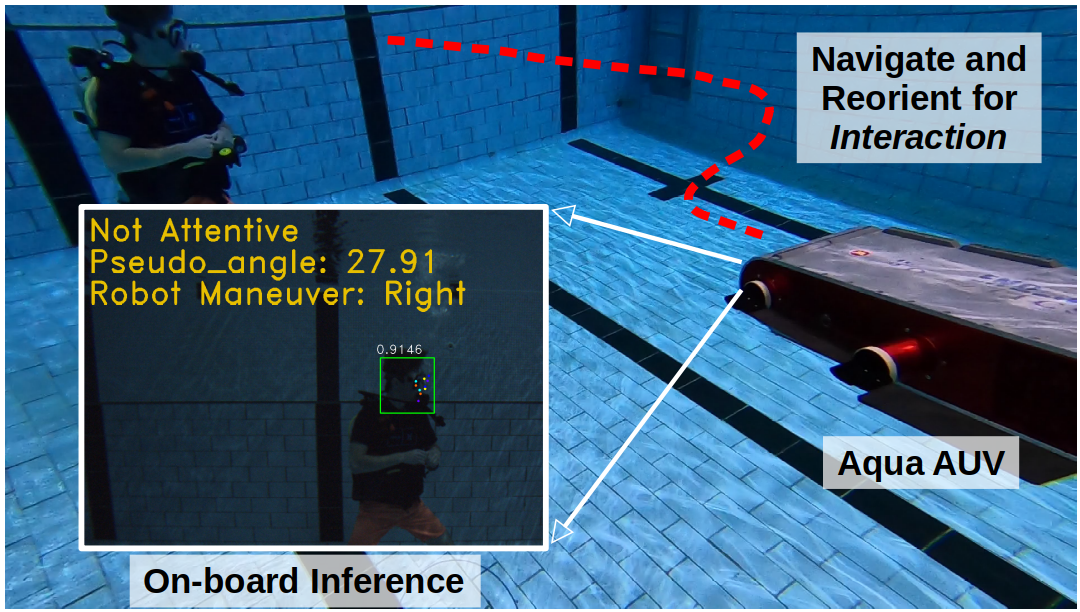
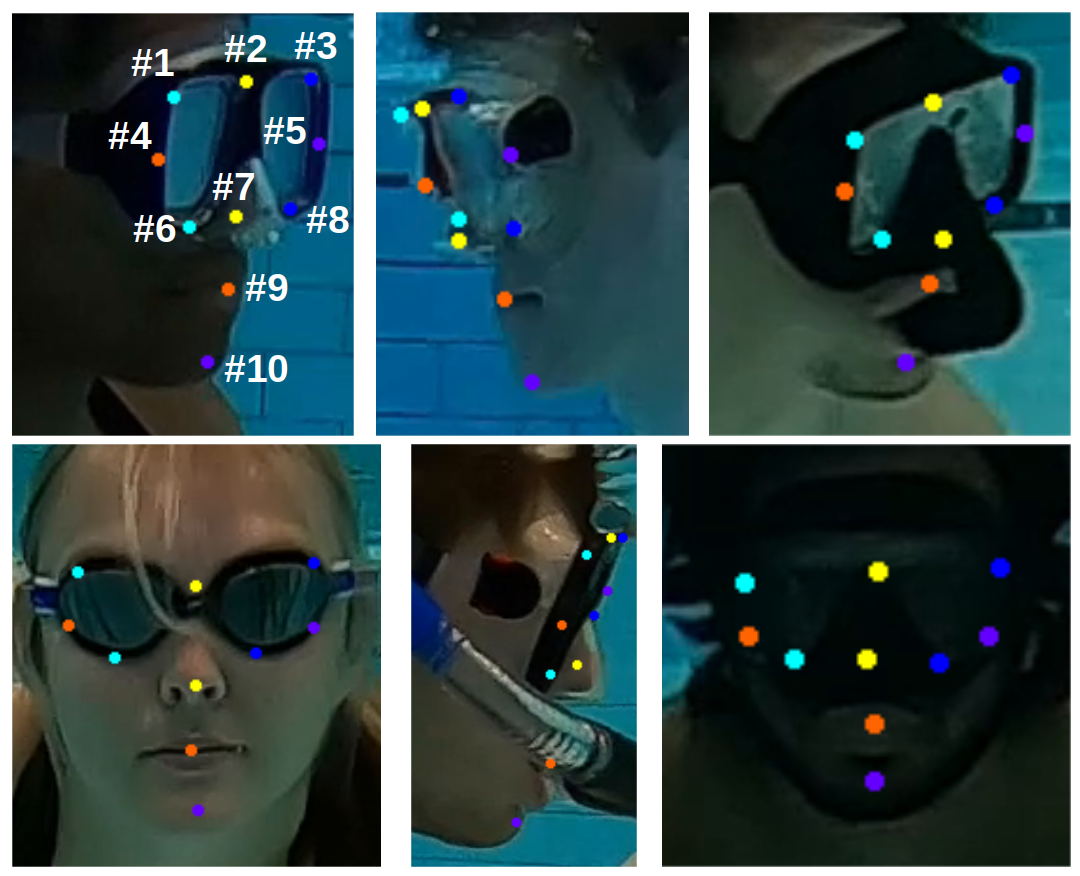
In this project, we propose a diver attention estimation framework for AUVs to autonomously detect the attentiveness of a diver and then navigate and reorient itself, if required, with respect to the diver to initiate an interaction. The core element of the framework is a deep neural network (called DATT-Net) which exploits the geometric relation among 10 facial keypoints of the divers to determine their head orientation. We design the network taking inspiration from a robust state-of-the-art face detection algorithm, called RetinaFace [2]. To facilitate the training of DATT-Net, we prepare a diver attention (DATT) dataset which contains 3,314 annotated underwater diver images. The images have a resolution of 1920 × 1080 pixels and are collected from multiple closed-water pool trials using GoPro cameras. Fig. 2 shows a few annotated samples from the DATT dataset.
Our on-the-bench experimental evaluations (using unseen data) demonstrate that the proposed DATT-Net architecture can determine the attentiveness of human divers with promising accuracy. Our real-world experiments also confirm the efficacy of DATT-Net which enables real-time inference and allows the AUV to position itself for an AUV-diver interaction. Detailed information can be found in the paper.
Demo:

Paper (preprint): https://arxiv.org/abs/2209.14447
Code: https://github.com/IRVLab/DATT-Net
DATT dataset: https://drive.google.com/file/d/1RGR1yNg6qv0XZQWajBkDRTRtxakv2fhB/view?usp=sharing
References:
[1] M. Fulton, J. Hong, and J. Sattar, “Using Monocular Vision and Human Body Priors for AUVs to Autonomously Approach Divers,” in 2022 International Conference on Robotics and Automation (ICRA), 2022, pp. 1076–1082.
[2] J. Deng, J. Guo, E. Ververas, I. Kotsia, and S. Zafeiriou, “Retinaface: Single-shot multi-level face localisation in the wild,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 5203–5212.