Our human-robot interaction (HRI) capabilities all rely on the ability to reliably and quickly detect divers. This project uses the new video diver dataset, VDD-C, to train and analyze various state-of-the-art deep neural networks to determine how best to detect divers for our HRI needs.
The VDD-C dataset was created with the goal of capturing and analyzing video diver data. This is crucial for robotics applications, since robots robots receive visual information as temporally sequenced frames of video data, rather than isolated images free of tempoarl context. We are also interested in video data because it captures divers at a variety of locations and rotations. This is illustrated by comparing the locations of divers in VDD-C (left) to the locations of divers in our previous dataset, DDD (right):

.
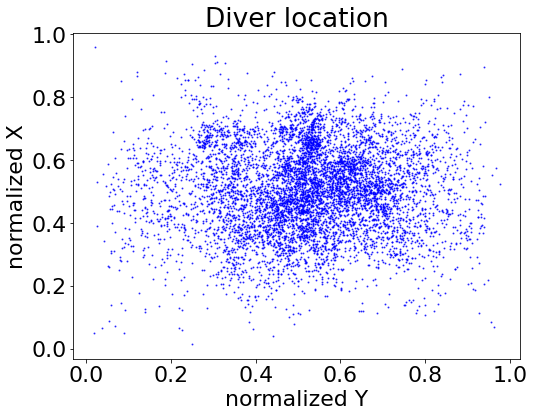
We also compare the performance of models trained on VDD-C and those trained on our previous dataset, DDD. Results indicate that models trained on VDD-C do well on both the VDD-C and DDD test sets, while models trained on DDD do not do very well on the VDD-C test set. This indicates that the VDD-C dataset is more varied and includes more information than the DDD dataset.
We also train and test a variety of state-of-the-art models on VDD-C, including several versions of Single Shot Detector (SSD) and You Only Look Once (YOLO), which are two very popular choices for realtime inference on robotic platforms. We also train Faster R-CNN to get an idea of performance on two-stage models, and LSTM-SSD to see if we can gain any benefits from leveraging temporal information during training and inference. We evaluate these models using mean average precision (mAP) and Intersection Over Union (IOU).
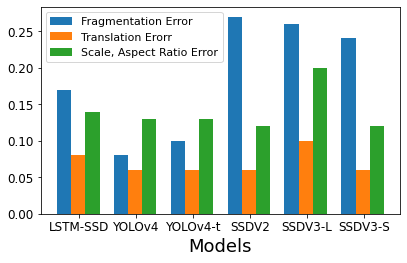
We are also interested in how well these models perform on video data. Specifically, we measure their temporal stability with three stability metrics: (1) fragmentation error, which describes how consistently each diver is detected (divers who are inconsistently detected over time contribute to higher fragmentation errors); (2) translation error, which describes how consistently the detected bounding box is located with respect to the ground truth; and (3) scale and aspect ratio error, which describes how consistently the bounding box is sized with respect to the ground truth. Results indicate that while the SSD models had relatively high mAP, they do not perform as well as YOLO and LSTM-SSD with respect to stability:
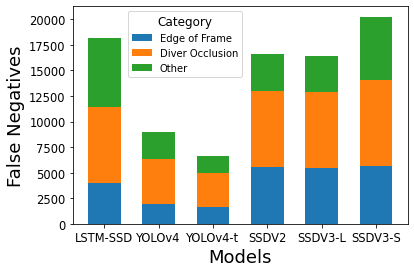
Additionally, we are interested in error cases for these models, and in particular, when these models fail to detect divers. Two common cases that result in false negatives are diver occlusions (where one diver is in front of another and partially blocking the other diver from view) and divers who are only partially in the frame. We visualized how many false negatives in each of the models are accounted for by these two error cases:
Finally, we test the frames per second (FPS) inference speed of the realtime-capable models in order to determine their feasibility for onboard robotic applications:
Overall, we conclude that YOLOv4-tiny is an excellent choice for many of our HRI applications due to its high recall, fast inference speed, and low stability error. In cases where stability is less important and higher mAP is valued, and we can afford to spend a bit more time on inference, we may choose SSDv3-L.