Over the last several decades, applications of autonomous underwater vehicles (AUVs) have multiplied and diversified (e.g., environmental monitoring and mapping, submarine cables and wreckage inspection, search and navigation), driven by ever-increasing on-board computational power, increased affordability, and ease of use. The majority of these applications involve multiple AUVs and/or their human diver companions, often interacting with one another to work effectively as a team. Thus, robust underwater human-to-robot and robot-to-human interaction capabilities are of utmost value. A common language comprehensible to both humans and other AUVs would greatly enhance such underwater multi-human-robot (m/HRI) missions (see Fig. 1).

In a recent work [1], it is shown that two AUVs can communicate between them using sequences of robot poses, however, it is unknown whether a human would understand this communication or not. In this project, we propose to use robot motion to design gestural messages as shown in [2], for both robot-to-human and robot-to-robot communications. We have designed these messages in simulated underwater environments, using computer-aided design (CAD) renderings of a six-legged AUV named Aqua. Additionally, we implement the gestural messages on board an actual Aqua robot using the Robot Operating System (ROS). Vid. 1 demonstrates two gestural messages performed in both simulation and a real underwater environment.
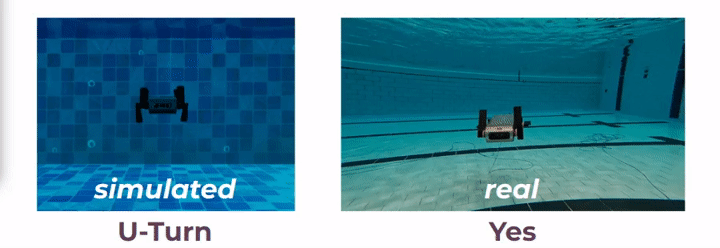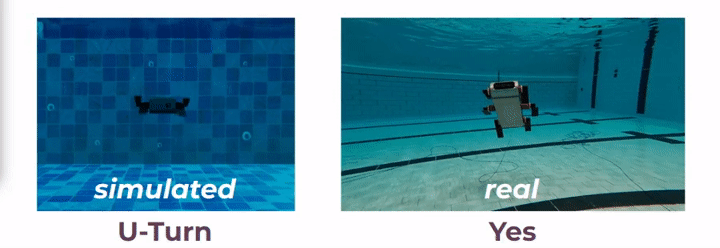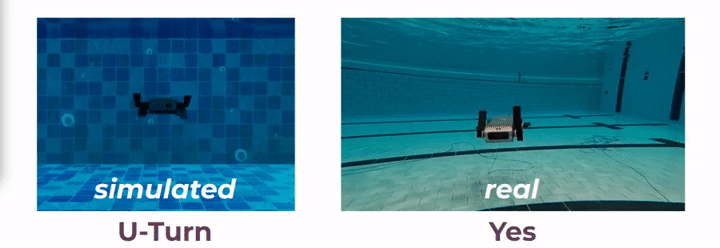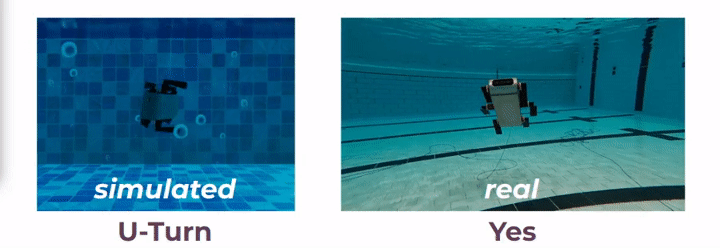
For a robot to interpret these messages, we propose a recognition network, Robot-to-Robot Communication Network (RRCommNet), which learns salient spatio-temporal features from the gestural messages using a self-attention mechanism. We leverage techniques from state-of-the-art activity recognition models, such as [3, 4]. After training RRCommNet on simulated and real-world data, our experiments show the recognition accuracy of RRCommNet to be approximately 94% on simulated data and 83% on real data (closed water pool environment). Vid. 2 shows the qualitative performance of the proposed network. Detailed information can be found in the paper.

Paper (preprint): https://arxiv.org/pdf/2207.05331.pdf
Code: https://github.com/enansakib/rrcommBibTex:
@inproceedings{enan2022robotic,
author={Enan, Sadman Sakib and Fulton, Michael and Sattar, Junaed},
booktitle={2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
title={{Robotic Detection of a Human-Comprehensible Gestural Language for Underwater Multi-Human-Robot Collaboration}},
year=2022,
pages={1-8}}
References:
[1] K. Koreitem, J. Li, I. Karp, T. Manderson, and G. Dudek, “Underwater Communication Using Full-Body Gestures and Optimal Variable-Length Prefix Codes,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 8018–8025.
[2] M. Fulton, C. Edge, and J. Sattar, “Robot Communication Via Motion: Closing the Underwater Human-Robot Interaction Loop,” in 2019
International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 4660–4666.
[3] M. E. Kalfaoglu, S. Kalkan, and A. A. Alatan, “Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition,” in European Conference on Computer Vision. Springer, 2020, pp. 731–747.
[4] R. Girdhar, J. Carreira, C. Doersch, and A. Zisserman, “Video Action Transformer Network,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 244–253.