Abstract
Rolling shutter distortion is highly undesirable for photography and computer vision algorithms (e.g., visual SLAM) because pixels can be potentially captured at different times and poses. In this paper, we propose a deep neural network to predict depth and row-wise pose from a single image for rolling shutter correction. Our contribution in this work is to incorporate inertial measurement unit (IMU) data into the pose refinement process, which, compared to the state-of-the-art, greatly enhances the pose prediction. The improved accuracy and robustness make it possible for numerous vision algorithms to use imagery captured by rolling shutter cameras and produce highly accurate results. We also extend a dataset to have real rolling shutter images, IMU data, depth maps, camera poses, and corresponding global shutter images for rolling shutter correction training. We demonstrate the efficacy of the proposed method by evaluating the performance of Direct Sparse Odometry (DSO) algorithm on rolling shutter imagery corrected using the proposed approach. Results show marked improvements of the DSO algorithm over using uncorrected imagery, validating the proposed approach.
Methodology
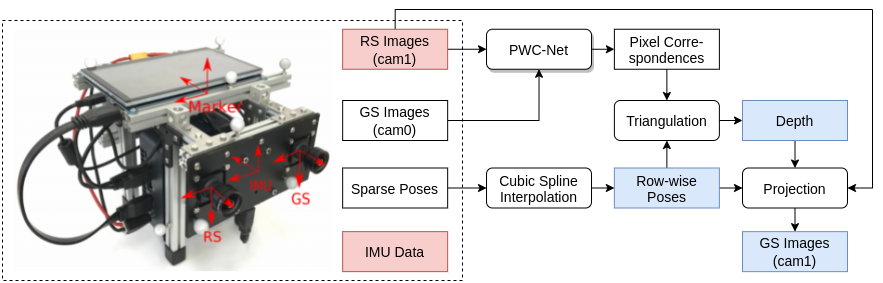
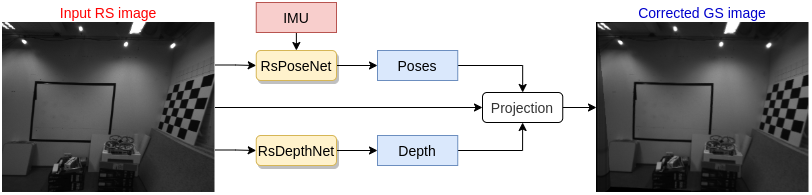
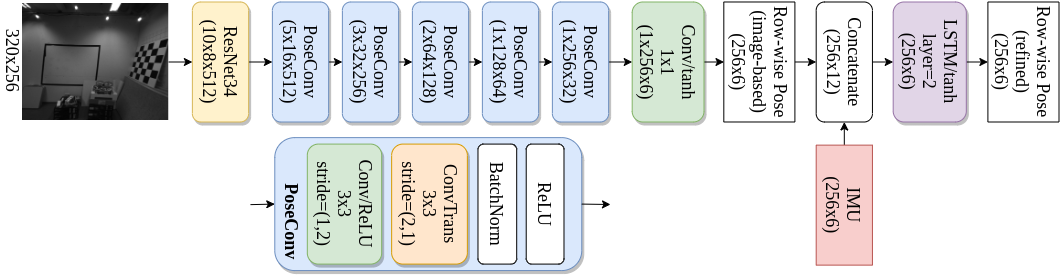
Results
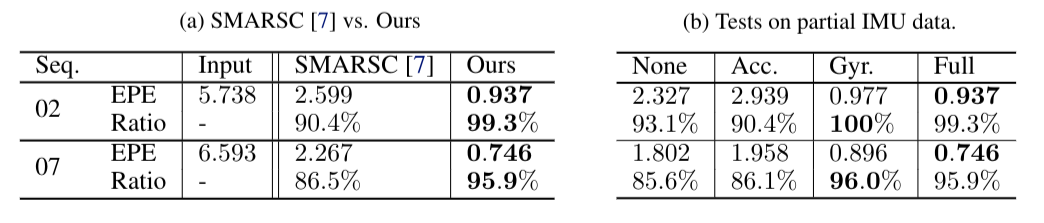
Data Generation Verification

Network Evaluation

Links
Paper(CoRL21)